The student assistants play a crucial role in processing the video data. Here is a description of some of the steps they are responsible for. For an overview, check out the diagramme to the right.
Audio Cleaning
Recordings are often done outdoors and contain distracting background noise that drowns out the voices of the children - noise from cicadas or birds; from wind, rain, running water or bonfires; or from people cutting down trees or constructing a hut. We use a programme to 'clean' such audio files in order to recover the voices of the children.


In the original recording the loud buzzing of a cicada makes it hard to hear the child speak →
With audio cleaning the buzzing is significantly reduced →
Metadata
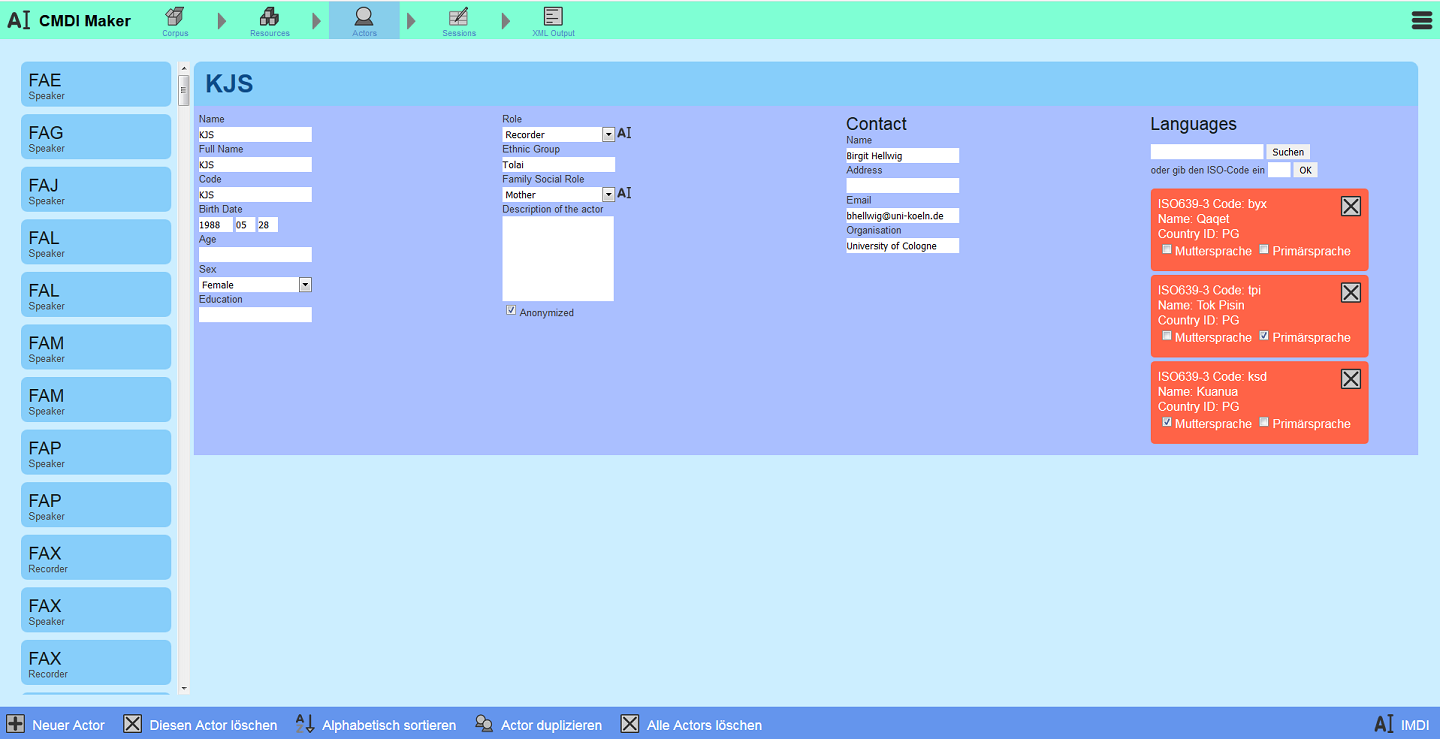
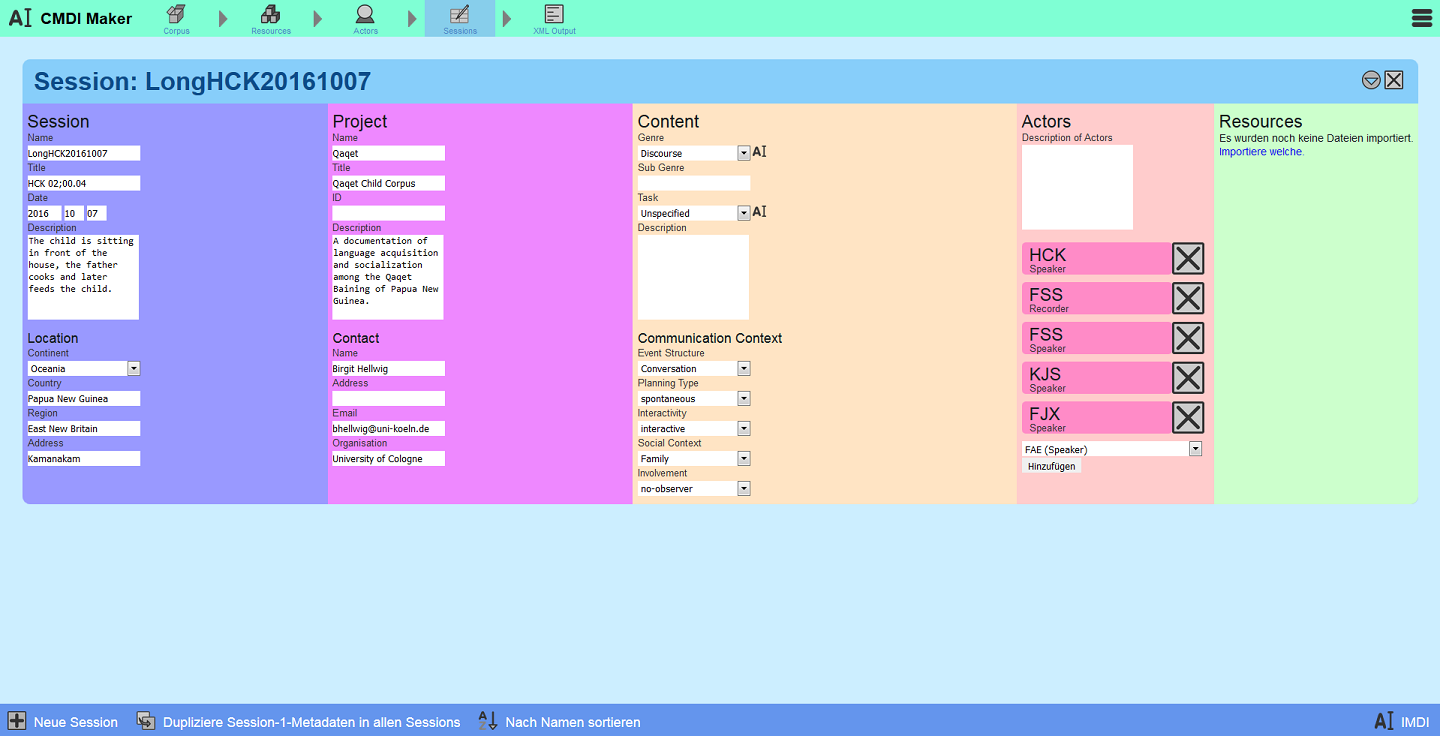
Every video has a corresponding metadata file, which at its most basic is a record of who's in the video, what they're talking about and when. We collect the information from the researchers and enter it into special programmes.
Initial Segmentation

We prepare the recordings so that our associates in Papua New Guinea can transcribe them. We segment them into utterances, and assign each utterance to the correct speaker. Each utterance receives a number and can be listened to individually.
Computerization


After our associates in Papua New Guinea have transcribed the utterances, the notebooks are brought back to Cologne, where we scan and archive them. We enter the handwritten transcripts and Tok Pisin translations into the computer.
Transcribing and Glossing
One of the many steps that follow is editing the original transcription. We aim to produce a transcription that precisely corresponds with the actual utterances. Hence, every small deviation from a target pronunciation of words or phrases is represented in the transcription. Accordingly, our task is to listen as closely as possible to what people say. Sometimes, you might wonder how many times a child can say the same thing in so many different ways within a quite narrow time frame. Listen to the example below to get an idea of how much variation there can be.
Try to transcribe the utterances yourself, and afterwards look at how we transcribed it (using the Qaqet orthography, click to unfold):
Final product
After the transcript has been through all these stages and more, it will contain multiple tiers and looks like this.